Introduction
- The temporal segment networks framework (TSN) is a framework for video-based human action recognition.
- TSN effectively models long-range temporal dynamics by learning from multiple segments of one video in an end-to-end manner.
- Two new modalities are introduced for action recognition: warp flow and RGB diff.
- TSN established new state-of-the-art perforamnce on UCF101 and HMDB51 benchmarks [results].
- We provide both Caffe [Caffe] and [PyTorch] implementation of the TSN framework.
- With TSN, we secured the 1st place in untrimmed video classification task of AcitivityNet challenge 2016.
- TSN models trained on the Kinetics Human Action Dataset also released. Kinetics pretrained TSN Models.
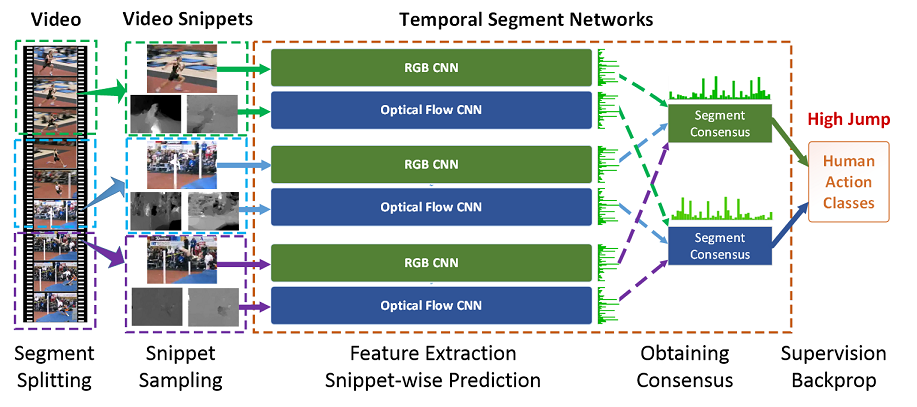
Experimental Results
We conducted action recognition experiments using segment number k=3 on two standard benchmark datasets: UCF101 and HMDB51. Click dataset names to see detailed results.* We do not use iDT in our experiments.
| Modality | RGB | Flow | Warp Flow | RGB + Flow (1:1.5) |
RGB + Flow + Warp Flow (1:1:0.5) |
|---|---|---|---|---|---|
| HMDB51 | 51.0% | 64.2% | 63.0% | 68.5% | 69.0% |
| UCF101 | 85.1% | 89.7% | 89.8% | 94.0% | 94.2% |
| Split 1 | Split 2 | Split 3 | Average of 3 Splits | |
|---|---|---|---|---|
| RGB | 54.4% | 50.0% | 49.2% | 51.0% |
| Flow | 62.4% | 63.3% | 63.9% | 63.2% |
| RGB + Flow (1:1.5) | 69.5% | 67.4% | 68.5% | 68.5% |
| * Note: it is fine to observe small differences in accuracy numbers of single streams, while the combined performance will be very stable. | ||||
| Split 1 | Split 2 | Split 3 | Average of 3 Splits | |
|---|---|---|---|---|
| RGB | 85.5% | 84.9% | 84.5% | 85.1% |
| Flow | 87.6% | 90.2% | 91.3% | 89.7% |
| RGB + Flow (1:1.5) | 93.5% | 94.3% | 94.5% | 94.0% |
| * Note: it is fine to observe small differences in accuracy numbers of single streams, while the combined performance will be very stable. | ||||
Incresing Segment Number (Journal Version)
In the ECCV publication we set the segment number to 3. In the recently submitted journal version of TSN, we increase the segment numerb to 5, 7, and 9 on UCF101 and ActivityNet v1.2. The results are obtained with only the RGB + Flow modalities.| Segment Number | RGB | Flow | RGB + Flow (1:1) | RGB + Flow (1:1.5) |
|---|---|---|---|---|
| 3 | 85.1% | 89.7% | 94.0% | 94.0% |
| 5 | 85.1% | 89.7% | 94.5% | 94.6% |
| 7 | 85.4% | 89.6% | 94.6% | 94.9% |
| 9 | 85.3% | 89.6% | 94.8% | 94.9% |
| Segment Number | RGB | Flow | RGB + Flow (1:1) |
|---|---|---|---|
| 3 | 83.6% | 70.6% | 86.9% |
| 5 | 84.6 | 72.9% | 87.6% |
| 7 | 84.0% | 72.8% | 87.8% |
| 9 | 83.7% | 72.6% | 87.9% |
Real-Time Action Recognition
The RGB diff modality is obtained by stacking difference frames of five continuous RGB frames. It requires no optical flow extraction, which is preferable for real-time action recognition.| Speed (on GPU) | UCF101 Split 1 | UCF101 3 Splits Average | |
|---|---|---|---|
| Enhanced MV [1] | 390 FPS | 86.6% | 86.4% |
| Two-stream 3Dnet [2] | 246 FPS | - | 90.2% |
| RGB Diff w/o TSN | 660FPS | 83.0% | N/A |
| RGB Diff + TSN | 660FPS | 86.5% | 87.7% |
| RGB Diff + RGB (both TSN) | 340 FPS | 90.7% | 91.0% |
[2] "Efficient Two-Stream Motion and Appearance 3D CNNs for Video Classification", Ali Diba, et. al., Arxiv Preprint.
Code
The Python codes and trained models are release as a full-fledged action recognition toolbox on Github.open_in_new Temporal Segment Network
We also provide a PyTorch reimplementation of TSN training and testing.
open_in_new TSN in Pytorch
Visualization
We visualized the parameters learned in CNNs using the DeepDraw toolbox.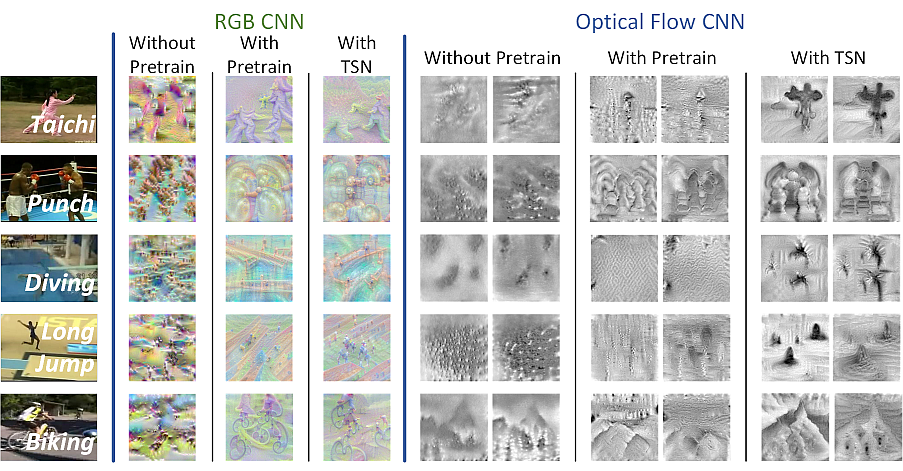
open_in_new More Visualization Results open_in_new How to draw them?
Citation
Please kindly cite the following paper if you find this project helpful.
@inproceedings{TSN2016ECCV,
author = {Limin Wang and Yuanjun Xiong and Zhe Wang
and Yu Qiao and Dahua Lin and Xiaoou Tang and Luc {Val Gool}},
title = {Temporal Segment Networks: Towards Good Practices for Deep Action Recognition},
booktitle = {ECCV},
year = {2016},
}
Related Projects
-
CES-STAR@ActivityNet 2016
We secured the first place of untrimmed video classification task in ActivityNet Large Scale Action Recognition Challenge 2016, held in conjunction with CVPR'16. The method and models of our submissions are released for research use.
[Github Link] [Notebook Paper] [Challenge Results] -
Caffe
Our modified version of the famous Caffe toolbox featuring MPI-based parallel training and Video IO support. We also introduced the cross-modality training of optical flow networks in this work.
[Github Link] [Tech Report] -
Dense Flow
A tool to extract RGB and optical flow frames from videos.
[Github Link] -
Enhanced MV for Real-Time Action Recognition
Enhanced MV-CNN is a real-time action recognition algorithm. It uses motion vector to achieve real-time processing speed and knowledge transfer techniques to improve recognition performance.
[CVPR16 Paper] [Project Page] -
Trajectory-Pooled Deep Descriptors (TDD)
The state-of-the-art approach for action recognition before TSN.
[CVPR15 Paper] [Github Link]
Contact
- For questions and inquiries, please contact:
- Yuanjun Xiong: yjxiong@ie.cuhk.edu.hk
- Limin Wang: lmwang.nju@gmail.com